Data acquisition mode
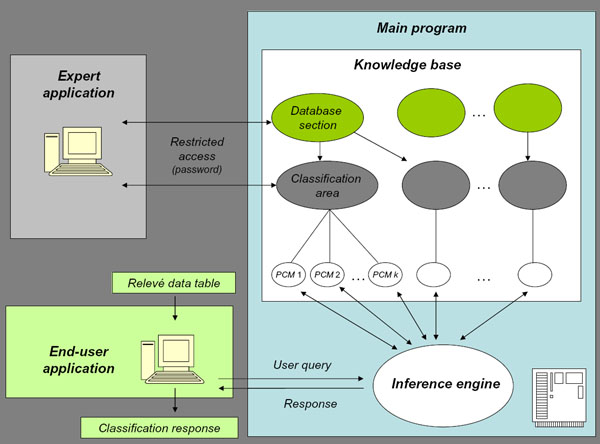
The knowledge
base of Araucaria contains two types of items: database sections, which are
simply containers of a relevé data, and classification areas, each
one containing a set of related PCM clusters. Such knowledge compartments
are remotely accessed and modified by vegetation experts, using the remote
expert application. Each database section or classification area conceptually
matches a high-level vegetation unit (e.g. defined physiognomically or corresponding
to a high-level syntaxon). Dividing the knowledge base into compartments allows
restricting management tasks to a specific scientist or group of scientists.
The relevé
data import procedure incorporates a data quality checking functions (e.g.
homogenizing nomenclature or deleting species entries marked as doubtful).
Once relevés are imported to the system they are stored in database
sections. The system provides an easy-to-use tool that allows experts to configure
new classification areas as described in the main text. The set of relevés
taken from database sections and used in each classification area is called
the training set. The configuration tool facilitates creating PCM clusters
by looking for relevés suitable as cluster seeds and facilitating the
"growing" of the cluster unit as described in the main text. Each
PCM cluster is finally accepted or rejected by the vegetation expert. The
system warns the expert user when two clusters become nested or show a certain
amount of overlap.
Query mode
The information
flow in a relevé classification query is fairly simple. First, a relevé
table must be available, by loading it from the user's file system or by retrieval
from a relevé data bank. The user then submits his/her relevé
table through the internet as a query. The main program receives the table
and applies the same checking protocol as described above for entering new
relevé data to the system. Relevés in this checked relevé
table are then classified and the main program returns a response to the client
application.
The system's classification procedure involves the following steps: